
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 챗GPT
- tableau
- GPT
- Python
- SQL
- Adobe
- datastudio
- Q
- daily
- diary
- ChatGPT
- openAI
- AZURE
- 데이터시각화
- 데일리
- 데이터분석
- 태블로
- review
- 구글애널리틱스
- 필사
- 북리뷰
- 서평
- Ga
- 빅쿼리
- bigquery
- 책리뷰
- 파이썬
- r
- 생성AI
- AWS
Archives
- Today
- Total
가볍게 배우고 깊게 즐기고 오래 남기기
Python || Pandas DataFrame의 describe() 사용 시 유의점 본문
Programming & Tip/Python
Python || Pandas DataFrame의 describe() 사용 시 유의점
Awesomist 2021. 1. 13. 08:31728x90
여러 개의 Series 유형을 하나로 묶은 DataFrame의 정보요약을 보고 싶을 때,
사용하는 Pandas의 DataFrame.describe()
(1) 데이터프레임(일반적으로 CSV 데이터) 전체의 요약정보 (주로 요약통계량)를 확인할 경우 ,

→ Count : 컬럼별 총 데이터수
mean / std : 컬럼별 데이터의 평균 / 표준편차
min / max : 컬럼별 데이터 최소값 / 최대값
25% / 50% / 75% : 백분위수의 각 지점으로, 분포를 반영해 평균을 보완하는 목적으로 사용
(2) 특정 컬럼/ 특정 시리즈의 요약정보를 확인할 경우 ,

→ Count : 총 데이터수
Unique : 중복없이 나오는 고유한 데이터값
Top : 가장 값이 많은 데이터 (최빈값인 항목)
Freq : 최빈 데이터의 실제 수 (Top의 개수, 최빈값)
은근히 빅데이터 현황 파악에는 (2)가 유용한데 많은 사람들이 (1)처럼 전체의 평균값 확인하는 용으로
거의 대부분 사용하는 듯 싶다.
(2)번의 코드 대신 아래 코드로 개별적으로 사용하는 경우가 생각보다 많아 아쉬운 마음에.
df['컬럼명'].unique()
# Distinct 값 확인, 즉 중복 제외한 값의 종류 확인용 (Unique와 동일)
df['컬럼명'].value_counts()
# 중복 포함해 전체 데이터 수 Count와 동일
df.dtypes # 데이터프레임 각 컬럼의 데이터 유형
+ 한 가지 팁 추가
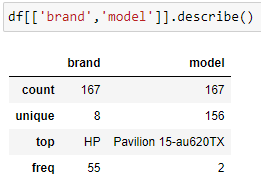
→여러 개의 컬럼(Series)의 요약정보를 확인하려면,
반드시 컬럼 전체를 리스트로 묶어 처리할 것


![[Microsoft 코리아] 마이크로소프트 Sculpt Ergonomic 무선마우스 스컬프트 에고노믹 인체공학 무선마우스 + 마우스패드증정, Sculpt Ergonomic mouse](https://image6.coupangcdn.com/image/affiliate/banner/6207f60f12e4abef7f23af9a9719b086@2x.jpg)



※ 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있습니다.
반응형
'Programming & Tip > Python' 카테고리의 다른 글
| [Error] riskfolio모듈 plot pie 에러 - " pie() got an unexpected keyword argument 'no (0) | 2023.01.22 |
|---|---|
| Python || 당신의 아나콘다 프롬프트에 '관리자 권한 실행'이 필요할 때 (에러 해결) (0) | 2022.07.20 |
| Python || 외부 DB에 연결용 - AWS / Netezza / Oracle / PostgreSQL / mysql (0) | 2021.10.26 |
| Anaconda Tip || Jupyter Notebook 연결 시 기본 브라우저 변경하기 (to 크롬브라우저) (0) | 2021.07.06 |
| Python || Pandas 행렬의 차원 확인하기 (with Shape 함수) (0) | 2020.11.20 |
'Programming & Tip/Python' Related Articles
more



Comments