
가볍게 배우고 깊게 즐기고 오래 남기기
AI for Fun || MS ChatGPT vs Google Bard : 챗GPT Bard 대답비교 - 두 AI가 생각하는 각자의 Q&A트렌드와 How to use well 본문
AI for Fun || MS ChatGPT vs Google Bard : 챗GPT Bard 대답비교 - 두 AI가 생각하는 각자의 Q&A트렌드와 How to use well
Awesomist 2023. 5. 13. 01:13
Google Bard 가 나와서 시끌시끌하다.
생각보다 낫다. 한국어 대응이 더 낫다는 말도 있고 하던데 직접 두 LLM 서비스 자연스러움을 한번 체크해보고 싶었다.
둘의 정보량 차이나 자연스러움을 한번 체크해보고 싶기도 하고 요즘
각자가 생각하는 스스로를 가장 잘 쓰는 법을 물어봤다.
나의 질문은 이것.
요즘 chatgpt/Bard에서 사람들이 주로 질문하는 내용은 어떤 거야?
그리고 너가 가장 자신있는 분야가 어떤건지 말해주면서 가장 잘 활용하기 위한 방법도 각각 알려줘
GPT에게는 Azure OpenAI 포함해서 4가지 모델에 질문을 넣어봤다.
(1) text-davinci-002-render-sha (https://chat.openai.com)
(2) gpt-3.5-turbo / (Azure)
(3) gpt4-8K (Azure)
(4) gpt4-32K / (Azure)
Bard는 실험버전으로 강화학습을 위한 것인지 하나의 질문에 총 3개의 답변이 도출되었다. (chatGPT도 API에서 가능)

Answer from ChatGPT text-davinci-002-render-sha (2023.05 기준)
* https://chat.openai.com/?model=text-davinci-002-render-sha


Good
- 가장 폭넓게 유저를 만나는 서비스 페이지인만큼 쉽게 읽히는 방향으로 hyperparameter를 조정한 것 같다.
- 깔끔한 요약과 문맥에 맞는 넘버링
Bad
- 개인적으로 번역어라도 text-davinci-003의 자연어 응답을 더 선호하기도 한 탓이겠지만 문장이 썩 마음에 들지 않는다.
- 이 친구가 이야기하는 요즘이 언제부터 언제인지 알려주지 않는다. 즉 실제 최신 질문 로그가 정상 업데이트가 된 건지 알 수 없다.

Answer from Azure OpenAI gpt-3.5-turbo
(@Azure Playground, 2023.3.1~)

Good
- 깔끔하고 명확한 대답,필요 없는 말로 토큰을 사용하지 않는다. (담백한 T자형 대답)
- 예시를 깔끔하게 정리해서 이해를 높여주는 부분
Bad
- 넘버링이 엉망이다. 현재 기준에서는 두 문장 이상의 복합적인 질문에 따라 넘버링을 하지 못한다.
- 말 자체를 분리하지 못해서 더 섬세하게 질문을 디자인해야할 것 같다. (ex) 질문방법을 알려줘
- 서비스를 휴먼처럼 느끼게 하려면 디테일한 Hyperparameter 조정이 필요해 보인다.
(실제로 여러 번의 노가다 결과 오늘 다르고 내일 다를 수 있었다. 이건 매번 랜덤으로 예외가 발견된다)

Answer from Azure OpenAI gpt4-8K
(@Azure Playground, 2023.3.14~)

Good
- 깔끔하고 명확한 대답,필요 없는 말로 토큰을 사용하지 않는다. (담백한 T자형 대답)
- 예시를 깔끔하게 정리해서 이해를 높여주는 부분은 동일하나 보다 문장형태로 대답한다.
Bad
- 마찬가지로 넘버링이 엉망이다. 현재 기준에서는 두 문장 이상의 복합적인 질문에 따라 넘버링을 하지 못한다.
- 원하는 자신 있는 분야를 하나를 선택하지 않는 걸 보아 섬세하게 질문을 디자인해야할 것 같다. (ex) 질문방법을 알려줘
- 3.5 turbo 보다는 Hyperparameter조정은 적을 것 같다.
- 발을 빼는 멘트가 추가되었다.
Answer from Azure OpenAI gpt4-32K
(@Azure Playground, 2023.3.14~)

Good
- 답변이 허락하는 한에서 정보를 꽉꽉 담아 넘버링이 더 많다.
- 깔끔하고 명확한 대답,필요 없는 말로 토큰을 사용하지 않는다. (담백한 T자형 대답)
- 예시를 깔끔하게 정리해서 이해를 높여주는 부분은 동일하나 보다 문장형태로 대답한다.
- GPT4-8K와 가장 큰 차이는 학습량에 투여가능한 토큰이라는 점을 감안하면 내용은 똑같다
Bad
- 마찬가지로 넘버링이 엉망이다. 현재 기준에서는 두 문장 이상의 복합적인 질문에 따라 넘버링을 하지 못한다.
그렇다면 Bard는?

Answer from ChatGPT Bard (2023.05 기준)
* https://bard.google.com/
- 개인적인 느낌은 창의성이나 어떤 유연한 대답을 지향하는 느낌
chatGPT의 Temperature = 0.5 이상일때와 유사한 대답으로 보인다.
(답안1)

(답안2)
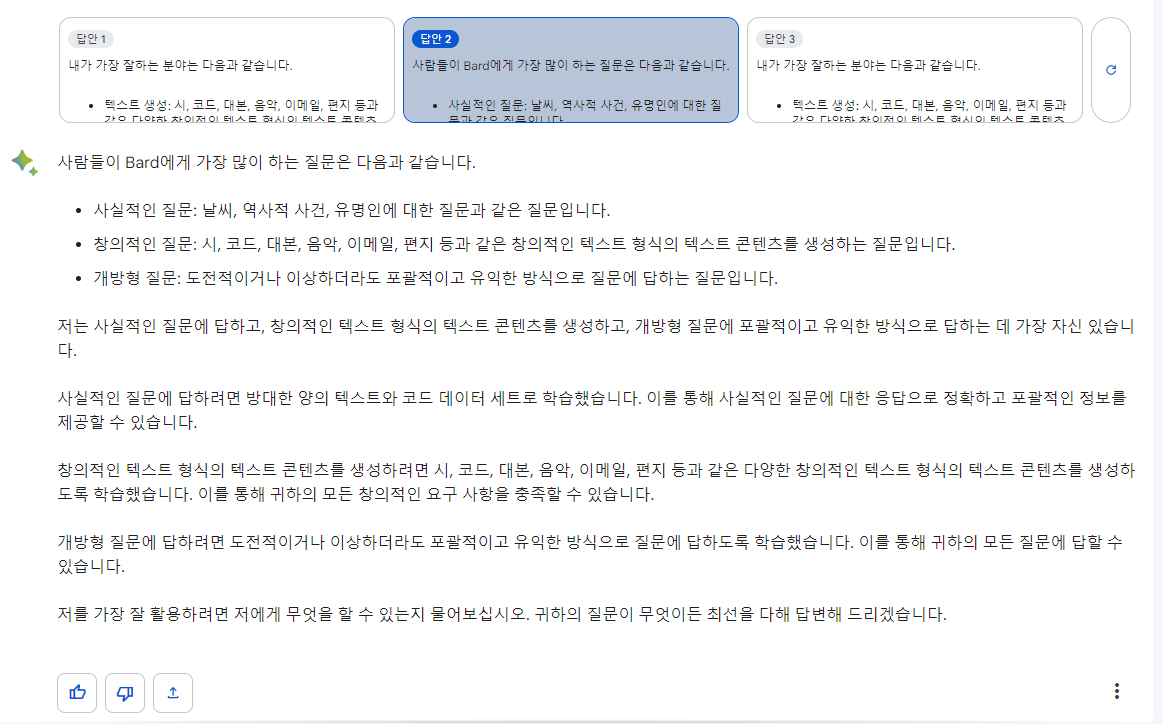
(답안3)

Good
- 너가 뭘 좋아할지 몰라서 다 준비해봤어
※ 참고 : chatGPT 페이지에서만 되지 않을 뿐 openAI API로 Hyperparameter 설정시 응답개수 조절이 가능하다.
- 넘버링 대신 글머리라는 머리좋은 선택을 했다.
- 최선을 다하는 편
Bad
- 반존대하는편
- Top list를 아직 알 수 없었고 뭉뚱그려서 대답을 한다.
- 즉, 최선을 다하지만 알맹이가 없는 편 (실험버전을 떼내고 난 후가 관건일 것 같다)
Answer from ChatGPT text-davinci-002-render-sha (2023.05 기준)


물론 학습기간에 한계가 있으니 Bard를 모를 수 밖에 없다.
그나저나 Bard College는 이름을 잃었다. 구글 상단은 구글 Bard가 장악했으니 ㅠㅠ
그런데 문득 궁금해졌다.
1) Bard는 후발주자기도 하고 구글 어시스턴트도 관리하고 있으니이것만큼은 좀더 센스 있는 대답을 기대할 수 있지 않을까 싶었다.
2) Azure의 다른 모델 특히 올해 3월 이후 업데이트 된 것들은 커버하는 대답을 할까?
우선 GPT,
놀랍게도(또는 자본주의답게도) Azure 사이드는 Bard 관련 데이터가 업데이트 되어있었다 !
Answer from Azure OpenAI gpt-3.5-turbo
(@Azure Playground, 2023.3.1~)

특징
- 역시나 강력한 T자형 답변 , 기세가 마음에 든다.
vs
Answer from Azure OpenAI gpt4-8K
(@Azure Playground, 2023.3.14~)

특징
- 읽다보니 이 친구 논리 그럴 듯하군 싶다(문과형 답변)
- 예시로 든 이유도 조금은 달라진 것을 확인할 수 있다.
- Bard를 은근하게 까지만 발을 빼는 멘트의 GPT4답게 평화주의자로 마무리한다. (다소 정치적인 AI)
vs
Answer from Azure OpenAI gpt4-8K
(@Azure Playground, 2023.3.14~)

특징
- 마찬가지로 읽다보니 이 친구 논리 그럴 듯하군 싶고 핵심 이유는 유사하다.
- 조금은 부드러운 표현이 생겼다. (언어지원-> 다양한 언어지원 / 학습능력 -> 지속적인 학습 등등)
- Bard를 은근하게 까지만 발을 빼는 멘트의 GPT4답게 평화주의자로 마무리한다.
- 결론적으로 좀더 고도화된 정치적인 AI가 되었다.
vs
그리고 대망의 Bard,
추천순위에 따라 3개의 답안을 생성해 보여준다.
(답안 1)

(답안 2)

(답안3)

특징
- 질문이나 아이디어를 얻을 때 답안 2~3까지 읽을만 하다. 유연한 응답은 생각보다 알맹이가 없다.
- Bard에 대한 자부심, GPT보다는 객관적인 증거로 승부하는 대답.(3번답안) 논리적이고 객관적일수록 반복된 문장으로 어감이 좀 어색하다.
모델이 많이 오픈된 MS의 GPT랑 지금 베타버전의 Bard를 비교할 수는 없겠지만
Azure를 통해 모델을 더 적용해본 결과 지금 기준으로 내 개인적으로 선호하는 응답은 chatGPT Win이다.
사람에게 전달하기 위한 썰 풀때 chatGPT ,
그리고 근거대응능력을 보았을때 합리적인 내용의 검토를 하거나 리서치를 진행할 때 Bard 가 의외로 쓸모있는 아웃풋을 좀더 기대해볼 수 있을 것 같다.
Bard도 근시일내 베타를 떼어낸 본 버전이나 모델이 추가 업데이트가 되면 분명 폭발적인 변화가 있을 것 같다.
다만 구글은 비용 관점에서 얼마나 대중들에게 비수익화 영역에서도 오픈할 것인가가 궁금하다.
다른 것은 몰다도 구글의 AI는 강력하니까 유료버전 GCP같은 곳에서나 좋은 결과가 인입될 수도 있다는 생각이 든다.
※ 파트너스 활동을 통해 일정액의 수수료를 제공받을 수 있습니다.


